
Hoe datahonger en filterbubbels ons dagelijks leven beïnvloeden
– over regulering & invloed van filterbubbels
In 1985 kocht mijn vader zijn eerste computer. Een zwarte achtergrond, amberkleurige letters. Meer was het in het begin niet. Hij was lid van een club techneuten, tegenwoordig zouden we ze nerds noemen, toen waren het hobby-pioniers. Het was geen garage in Silicon Valley, maar er werd wel informatie uitgewisseld. De gedachte van het internet als ‘gedeelde plek voor iedereen’ werd er doorleefd. Thuis maakte ik, vanaf mijn vaders schoot, de ontwikkelingen van de personal computer mee. Van fascinerende screensavers met treinen tot mijn eerste ervaring met internet.
Gepersonaliseerde waarheid
Het was voor iedereen duidelijk: met de komst van het internet zou de wereld met elkaar verbonden zijn. Informatie vinden zou voor iedereen mogelijk worden, maar bovenal een stuk gemakkelijker. Iedereen had toegang tot dezelfde informatie, het internet was ‘van ons’. Een democratische droom, want die beschikbare informatie zou de ontwikkeling naar geïnformeerde en mondige burgers enorm in de hand werken. En dat deed het. Tot op zekere hoogte misschien, maar we kunnen zonder twijfel stellen dat de komst van internet onze samenleving niet onaangeroerd heeft gelaten.
Het tegenstrijdige is echter dat het door diezelfde enorme hoeveelheid informatie onmogelijk bleek om aan absolute waarheidsvinding te doen. En dat zit datzelfde democratische proces soms in de weg. Het overzicht raakte voor de gewone internetgebruiker zoek en professionele (journalistieke) platforms kwamen op om ook de internet-informatie te duiden. De rol van journalisten als gatekeeper (poortwachter) van het internet was geboren. Hierdoor bepaalden zij, door het nieuws te selecteren, wat er in de media verscheen (Pariser, 2011-a).
Het vertrouwen in deze beroepsgroep daalt nu echter gestaag en heeft inmiddels wereldwijd een dieptepunt bereikt (Edelman, 2017). Liever zoeken we via Google zelf het antwoord op of gaan we af op de mening van onze ‘vrienden’ op sociale media. Daarbij bepalen onze zoektermen de zoekresultaten en welke vrienden we toevoegen bepaalt hoe onze tijdlijn er uitziet. Tenminste, daar gaan we vanuit.
In werkelijkheid is alles wat we te zien krijgen al voor ons geselecteerd, op basis van ons gedrag in het verleden. ‘Gepersonaliseerd’ noemen we dat. Hierdoor kan het zijn dat bij dezelfde zoektermen andere zoekresultaten naar boven komen of van sommige vrienden veel posts (geplaatste berichten) te zien zijn en van anderen weinig. Zonder uw toestemming bepalen internetbedrijven wat wel en wat niet interessant is. Nog verontrustender is dat u niet weet wat u niet ziet. Alles wat buiten de selectie valt is ontastbaar en onzichtbaar. We leven in een online luchtbel waarin filters alleen gelijkgestemden laten meepraten. De wereld waarin we steeds vaker en langer vertoeven, de onlinewereld, gaat niet meer over ‘ons’. Het gaat nu over ‘mij’. We leven online in een filter bubble. [1]

Visuele weergave van een filterbubbel.
Afbeelding: Eli Pariser’s Ted Talk.
57 ‘signalen’ en úw informatiebehoefte
Uw gloednieuwe telefoon weet exact waar u bent, met wie u belt en hoe vaak, wat u leest en beluistert. Facebook weet waarop u klikt, hoe lang u op een pagina blijft, welke vrienden u het aardigst vindt, waar u heen gaat op vakantie, met wie en hoe vaak. Het bedrijf uploadt de gegevens van al uw contacten, Facebookgebruiker of niet, naar een eigen server (Pleij, 2017). Daarvoor heeft u immers toestemming gegeven toen u de ‘gratis’ dienst ging gebruiken.
De zoekmachine Google volgt elke stap die u zet en elk woord dat u intypt en plaatst vervolgens betaalde advertenties, gebaseerd op zoekgedrag, bovenaan de pagina met resultaten. Ook de andere, niet betaalde, zoekresultaten worden gerangschikt op basis van de opgeslagen data. Daarvoor gebruiken worden volgens Eli Pariser (2011-b, p. 32), de auteur van het boek The Filter Bubble, 57 ‘signalen’ gebruikt die elk relevant zijn voor de informatiebehoefte van de gebruiker. ‘Signalen’ zoals de zoekgeschiedenis of welke browser gebruikt is, maar ook de fysieke locatie en het tijdstip van de dag. En niet alleen als het Google-account ingelogd staat: ‘Even if you were logged out, it would customize its results, showing you the pages it predicted you were most likely to click on’ (Pariser, 2011-b, p. 34). Dus zelfs als twee mensen op hetzelfde moment dezelfde zoekterm invoeren, dan verschillen de resultaten. Zelfs het aantal resultaten verschilt. Zo ontstaan er ‘parallel but separate universes’ (Pariser, 2011-b, p. 37).
Een voorbeeld uit de offlinewereld kan helpen om het effect van deze selectie te duiden. Nederlandse ouders mogen zelf kiezen welke school geschikt is voor hun kinderen. Stelt u zich voor dat een Amsterdams gezin de keuze heeft uit vijf scholen. Het staat ze vrij om te kiezen, dus in principe kunnen ze elke school kiezen. Zodra we besluiten dat van de vijf scholen, er drie onbekend zijn bij de ouders omdat we deze niet aan hen tonen, kunnen ze nog steeds alle scholen kiezen. Al zijn het er dan nog maar twee.
De vrijheid om zelf keuzes te maken is een groot goed, maar externe factoren bepalen in grote mate onze keuzes. Waaruit kan ik kiezen? Hoe goed ben ik geïnformeerd? Wie bepaalt wat relevant voor mij is? Dat zijn vragen die gesteld moeten worden, want als een commercieel bedrijf bepaalt welke scholen het Amsterdamse gezin ziet, in welke volgorde en op welke manier, dan moet de onafhankelijkheid van dit platform serieus in twijfel worden getrokken. Toch bepaalt Google online in grote mate de omgeving waarin we keuzes maken, de zogenoemde keuzeomgeving. Bovendien heeft het bedrijf volgens voormalig CEO Eric Schmidt ambities om in de toekomst een eenduidig antwoord te geven op de vraag: ‘Naar welke school moet ik mijn kind sturen?’ [2]
Niet alleen de zoekmachine verzamelt data. De kaartendienst Google Maps slaat op waar u geweest bent, hoe lang u onderweg was en weet soms ook bij wie u op bezoek was en hoe lang. Bij gebruik van het adresboek van Google bijvoorbeeld, of als u de afspraak in Google Agenda genoteerd heeft. Zelfs een privé-email scant Google op inhoud om op basis daarvan advertenties te verkopen. Wel hebben ze aangegeven ‘later dit jaar’ te gaan stoppen met het scannen van persoonlijke e-mails (Greene, 2017). Volgens de onafhankelijk tech-website Tweakers stopte het bedrijf in 2014 al met het scannen van de e-mails van bedrijven en overheden, die via Gmail verstuurd werden (Blauw, 2014).
Het doet denken aan een quote uit ‘The Secrets of Surveillance Capitalism,’ een artikel van Harvard Law-professor Shoshana Zuboff (2016): ‘Most Americans realize that there are two groups of people who are monitored regularly as they move about the country. The first group is monitored involuntarily by a court order requiring that a tracking device be attached to their ankle. The second group includes everyone else…’
Al deze data gebruiken internetbedrijven niet alleen om geld te verdienen aan de verkoop ervan, maar ook om te bepalen wat de gebruikers in de toekomst te zien krijgen. Advertenties van derde partijen worden gepersonaliseerd aangeboden, want: hoe meer het product aansluit bij uw behoefte, hoe waarschijnlijker het is dat u het gaat kopen. Internetwinkels als Amazon en onlinestreamingdiensten zoals Netflix investeren jaarlijks veel geld om surfgedrag te kunnen tracken. Dit verdienen ze ruimschoots terug door het aanbod af te stemmen op de interesse van iedere individuele klant. En niet alleen internetbedrijven begrijpen de waarde van dergelijke data. De huidige Amerikaanse regering kan voortaan bij visa-aanvragen het afstaan van mobiele-telefooncontacten en social-mediawachtwoorden verplicht stellen, aldus Reuters (Torbati, 2017).

2 miljard van de 3,5 miljard internetgebruikers heeft Facebook.
Afbeelding: Niels van Velde
De jeugd heeft de toekomst
Wereldwijd zijn er een kleine 3,5 miljard internetgebruikers (Statista, 2016). Een kleine 2 miljard daarvan zijn Facebookgebruikers (Statista, 2017a). Facebook bepaalt dus wereldwijd voor 57 procent van de internetgebruikers wat ze zien, wanneer ze het zien en hoe ze het zien. Onderzoeksbureau Edelman concludeert in de Edelman Trust Barometer van 2017 dat 54 procent van de ondervraagde Europeanen de zoekmachine eerder gelooft dan ‘human editors’. ‘In 2015 gebruikte bijna 40 procent van de ruim negen miljoen Nederlanders op Facebook het sociale medium als bron van nieuws,’ bleek volgens het NRC uit een onderzoek naar digitale nieuwsconsumptie door Reuters.
De impact is dus groot, zeker als het gaat over kwetsbare groepen. Newcom Research & Consultancy onderzocht het social-mediagebruik van Nederlandse jongeren. Facebook is erg populair (80 procent van de 15- tot 19-jarigen gebruikt Facebook). WhatsApp (Facebook Inc.) en YouTube (Google Inc.) zijn nog populairder met respectievelijk 96 en 86 procent (Veer, 2017).
Ook de Nederlandse jeugd wordt dus beïnvloed door de filters van internetgiganten als Facebook en Google. Het Nederlands Jeugdinstituut, een autoriteit op het gebied van jeugd- en opvoedingsvraagstukken, ziet geen probleem, eerder veel kansen in het gebruik van media: ‘Kinderen gebruiken media (…) vooral om met elkaar te communiceren en ervaringen, gedachten en meningen met elkaar uit te wisselen.’ Daarbij benoemt het instituut dat deze vormen van interactie via platformen als Whatsapp, Facebook, Twitter en andere sociale media kunnen plaatsvinden.
Privézaken. Beschikbaar voor iedereen
‘Persoonlijke informatie, die je niet zomaar met iedereen deelt.’ Zo zouden veel Nederlanders hun seksuele voorkeuren en date-gedrag kunnen omschrijven. Toch delen we ook dat massaal online. Opvallend gedrag, in een samenleving waarin algoritmen enorme invloed hebben en waar bedrijven gegevens per opbod verkopen. Waar u uw geliefde niet alleen in de bar tegen kunt komen, maar ook via Tinder [3] of OkCupid. [4] En ook die gebruiken algoritmen, met indrukwekkende datasets. Het algoritme van Tinder deelt haar gebruikers op in categorieën, bepaald door de mate waarin u begeerd wordt en gebruikt hiervoor uw Facebook-profiel. Tinder CEO Sean Rad bevestigde het bestaan van dit scoresysteem in een gesprek met Austin Carr van de Amerikaanse zakelijke nieuwssite Fast Company. ‘It’s not just how many people swipe right on you,’ legt hij verder uit. ‘It’s very complicated. It took us two and a half months just to build the algorithm because a lot of factors go into it’ (Carr, 2016). CEO Rad treedt niet in detail, maar Carr laat er weinig twijfel over bestaan waaruit deze ‘desirability score’ opgebouwd zou zijn. Hoeveel van de mensen bij wie u naar rechts swipet, doen dat ook bij u? Hoeveel niet? Heeft u een hoge opleiding, een functie met prestige of een hoog salaris? Alle informatie die u invult wordt langs dezelfde meetlat gelegd. Vrij vertaald: hoe sexy is uw profiel? En vergeet niet, elke swipe wordt bijgehouden, want wat deze simpele vingerbeweging in essentie meteen zegt is: ‘I find this person more desirable than this person’, zegt Tinder’s data analyst Chris Dumler (Carr, 2016). En dat voor een kleine 40 miljoen gebruikers, verdeeld over 196 landen, voor alleen Tinder (Romano, 2016).
Het totale wereldwijde aantal gebruikers van online dating diensten is lastig in te schatten, maar om een beeld te geven: ongeveer 151 miljoen (Statistica, 2017b; Statistica, 2017c) mensen downloadden in 2016 een van de online datingapps (Android en iOS opgeteld). Datingsite Badoo is de grootste, met 353,7 miljoen gebruikers (Badoo, 06/07/2017). Online dating heeft haar stigma de laatste jaren verloren en dat zien we terug in de cijfers.
Ook hier ontbreekt het bewijs of ook maar de garantie van het internetbedrijf dat ze zorgvuldig met de data om zullen gaan, dat ze geen verhulde motieven hebben. Het zou te ver gaan om Tinder op basis van het ontbreken van het genoemde bewijs te beschuldigen, maar stel dat ze op basis van bijvoorbeeld hun eigen geloofsovertuiging of etniciteitsvoorkeuren mijn profiel zouden bewerken? Dat ik alleen de singles te zien kreeg die Tinder doelbewust heeft uitgezocht? Voor zover wij weten is dit geenszins het geval, maar als dit verandert: hoe weten we dat dan? Tinder geeft geen inzage in haar algoritme: ‘bedrijfsgeheim’.
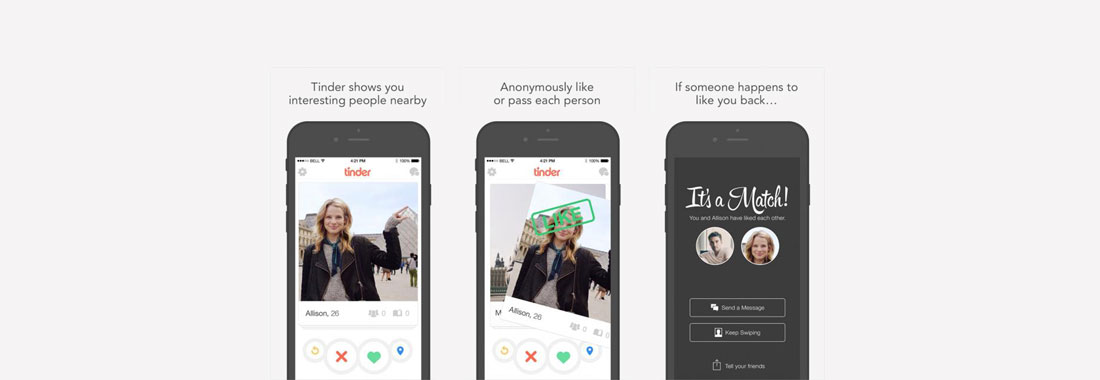
Swipe naar rechts en vind je match. Tinder weet wie jij leuk vindt.
Afbeelding: knowyourmobile.com
Waakhond aan een lijntje
Daar zien we opnieuw de parallellen met tegenhangers als Google en Facebook. Op dezelfde manier vertrouwen we allerlei, ook intieme en persoonlijke, gegevens toe aan bedrijven die we nauwelijks kennen, waarvan de motieven niet openbaar zijn en die geen democratische verantwoording afleggen. Het staat vast dat algoritmen voor een groot deel bepalen wat we zien: ‘(…) welk nieuws je ziet, welke zoekresultaten je krijgt, welke bronnen als betrouwbaar of als ongeloofwaardig worden bestempeld enzovoorts. Ze bepalen, kortom, voor een groot deel wat wij geloven, weten en vinden,’ zoals Rob Wijnbergen het zegt (Wijnberg, 2016).
De controlerende nieuwsmedia zelf, ook wel de waakhonden van de democratie genoemd, zijn steeds meer verweven met social-mediaplatforms. Onbedoeld én vrijwillig. Onbedoeld hebben Google’s zoekresultaten mede invloed op het aantal keren dat een artikel gelezen wordt. En vrijwillig: zelfs de meest kwaliteitsgerichte (staats)media gebruiken platforms als Facebook, Twitter en LinkedIn. Daar delen ze nieuws en gaan ze de discussie aan met hun lezers of kijkers. Ook kijken ze naar het aantal views (weergaven) en het aantal likes (vind ik leuks) om te beoordelen hoe een artikel gewaardeerd wordt. Rob Wijnberg (2016), hoofdredacteur van De Correspondent, zegt hierover: ‘Traditionele nieuwsmedia laten zich meer en meer leiden in hun keuzes en presentatie door wat het meest geliket, geshared of geretweet wordt. Tegelijkertijd zijn er nieuwe media ontstaan die hier volledig op zijn gebaseerd, variërend van mainstream (Buzzfeed, The Huffington Post) tot radicaal (Breitbart, Infowars). Met andere woorden: Google en Facebook bepalen, direct én indirect, welke informatie in welke vorm in welke mate wordt geconsumeerd.’ Hij concludeert zijn uiteenzetting over algoritmen met de woorden: ‘Waar is niet wat klopt. Waar is wat klikt’ (Wijnberg, 2016).

Gebaseerd op cover van ‘The Filter Bubble’
Afbeelding: Niels van Velde
Bubbelkritiek
Een gemiddelde Facebookgebruiker heeft toegang tot ongeveer 1500 posts per dag, maar bekijkt er maar 300. Dat concludeerde Victor Luckerson (2015) in zijn artikel in Time Magazine Het platform maakt een enorme selectie, want het wil er zeker van zijn dat deze 300 interessanter zijn dan de rest. ‘Facebook says it uses thousands of factors to determine what shows up in any individual user’s feed.’ (Luckerson, 2015). Andere grote databedrijven doen hetzelfde. Het effect dat ze daarmee in de hand werken is dat we niet langer zien wat we moeten zien, maar alleen wat we wíllen zien. Op Facebook zien we mensen die op ons lijken, op wie we het vaakst gereageerd hebben en met wie we interesses delen. Google ‘helpt’ ons door informatie voor te selecteren die voor ons ‘relevant’ is, maar vertelt er niet bij wat ze weglaat. Tinder belooft ons liefde op swipe-afstand, maar vertelt nauwelijks waar mogelijke matches op gebaseerd zijn. De wereld om ons heen wordt gepersonaliseerd, naar onze eigen smaak. Wat wij leuk vinden telt. Maar ook: wat wij vinden is waar.
Daarom de benoemde kritiek nogmaals op een rij:
1) Internetbedrijven gebruiken onze data voor niet-legitieme redenen;
2) Zelfs als de redenen legitiem zijn, is het ethisch twijfelachtig om gebruik te maken van de cognitieve zwakten van een gebruiker;
3) Er is een groot gebrek aan transparantie waarbij controle van algoritmen niet mogelijk is.
Een emotioneel experiment met uw tijdlijn
Hoe Facebook denkt over ethische normen, legitieme redenen en haar verantwoordelijkheid voor de content op de News Feed, bleek in juni 2014. Onderzoekers sleutelden aan de tijdlijn van bijna 700 duizend gebruikers om de mate waarin emoties ‘besmettelijk’ waren te achterhalen. Een deel van de gebruikers kreeg, zonder dat ze daarvan op de hoogte gesteld werden, een tijdlijn vol negatieve statusupdates te zien. Bij een ander deel stond het vol met positieve berichten. Niet alleen liet dit onderzoek zien hoe aanstekelijk emotie op Facebook is, maar het wijst ook uit hoe het bedrijf haar gebruikers als laboratoriumratten in een tredmolen laat rondrennen. Optimalisatie van de site is het hogere doel en dergelijke middelen zijn daarvoor blijkbaar toegestaan. Na de ophef denk ik dat Facebook vooral geleerd heeft van het publiceren van dit soort onderzoeken. Daar zijn ze voortaan iets voorzichter mee. Of dergelijke onderzoeken nog steeds plaatsvinden? Misschien wel op dit moment, op uw tijdlijn. Moeilijk is dat niet, bij veel posts geven mensen zelf aan hoe ze zich voelen door middel van ‘emotion-tags’. Hoe voelt u zich vandaag?
Cognitieve zwakten van de gebruiker
Een autonome beslissing is, volgens Karen Yeung (2016, p.7), professor bij King’s College London, een beslissing die door een mentaal competent en volledig geïnformeerd persoon wordt genomen. Daarnaast hebben psychologen en andere sociale wetenschappers meermaals aangetoond dat mensen die veel verschillende informatie krijgen, meestal niet rationeel en verstandig kiezen. Ze kiezen vaak voor de informatie die het eenvoudigste is (Brock & Balloun, 1967) en die onze eigen overtuigingen (her)bevestigen (Iyengar & Morin, 2006). Volgens onderzoeksbureau Edelman is het ‘four times as likely’ dat we informatiebronnen die onze standpunten of ons wereldbeeld tegenspreken, negeren (Edelman, 2017). Hiervan maken internetbedrijven gebruik, misschien onbewust, maar de impact blijft groot. Pleiten voor meer initiatief vanuit de gebruiker lijkt ook geen oplossing: naast de selectie door algoritmen gaan mensen actief op zoek naar informatie die bij hun beeld aansluit. ‘Mensen zoeken online hun eigen waarheid waarin ze graag blijven geloven,’ zegt een woordvoerder van Hoax-Wijzer, een website die de verspreiding van onjuiste nieuwsberichten bijhoudt (Gorris, 2016). Toch is het breed informeren van het publiek van groot belang. Dat zegt ook doctoraal kandidaat aan de Technische Universiteit Eindhoven, Marjolein Lanzing: ‘Privacy beschermt vrijheden die belangrijk zijn voor een ‘gezonde’ democratie, zoals de ontwikkeling van (afwijkende) meningen en gedachten, diverse versies van het goede leven, experiment, creativiteit en unieke persoonlijkheden’ (Lanzing, 2016).
Acuut transparantietekort
Transparantie werkt geen vertrouwen in de hand. Het werkt controleerbaarheid in de hand. En aangezien redenen tot vertrouwen in de privacy-overtuigingen van internetbedrijven ver te zoeken zijn, is daar grote behoefte aan. Heldere voorwaarden waarmee gebruikers akkoord moeten gaan is een eerste stap. Problematisch hierbij is dat bij het opstellen van de ‘terms and conditions’ met de grote variëteit aan mogelijkheden geen rekening kan worden gehouden. Dit simpelweg omdat sommige experimenten ontstaan door de beschikbaarheid van data. Die data zorgt er in sommige gevallen voor dat bedrijven op een andere manier over de mogelijkheden van deze datasets gaan nadenken. De privacyverklaringen op dat moment aanpassen, zonder daarbij opnieuw om toestemming te vragen, is een veelvoorkomende methode. Het gebruikmaken van de dienst is voldoende om instemming aan bedrijven te verlenen voor het opslaan en gebruiken van de data, zo is veelal de gedachte. Het aanbieden van een mogelijkheid om van de effecten van de wijziging uit te schakelen (‘opt-out’) is ronduit zeldzaam. Hiervoor moet de gebruiker zijn account en het gebruik ervan vaak opgeven.
Een specifieke melding voor één gespecificeerde aanpassing zou uitkomst kunnen bieden. Dat dit nauwelijks voor komt is mogelijk te verklaren door het feit dat de meeste hypernudges bij het bewustzijn ervan niet meer werken. Karen Yeung, de bedenkster van de term, refereert aan een ‘Big Data’-gedreven nudge als ‘hypernudge’. Dit omdat deze manier volgens haar behendig, onopvallend en krachtig is, zonder als opdringerig te worden ervaren (Yeung, 2016, p. 6). Het voorziet de gebruiker van een zeer gepersonaliseerde keuze omgeving. Verder wijst ze op de grote ongelijkheid tussen het databedrijf aan de ene en de individuele gebruiker aan de andere kant en de hoeveelheid mensen waarop de nudge invloed heeft. Facebook kan namelijk met één (algoritmische) hypernudge invloed uitoefenen op miljoenen gebruikers tegelijkertijd (Yeung, 2016, p.7).
Databedrijven en hun algoritmen functioneren als ‘black boxes’. De code wordt veelal beschermd als bedrijfsgeheim. De subtiele wijze waarop gebruikers verleid worden, is mijns inziens een van de belangrijkste redenen waarom burgers niet op de spreekwoordelijke barricaden klimmen. Als er sprake was van dwang, of beter gezegd als dwang ervaren werd, was internetprivacy niet langer het exclusieve domein van een selectieve groep critici geweest. Organisaties als Bits of Freedom proberen al enige jaren voet aan de grond te krijgen in het publieke debat, maar slagen daar slechts beperkt in door het onzichtbare karakter van de uitgeoefende invloeden van dergelijke databedrijven.
Datahonger ingeperkt
Het is april 2016 als er goed nieuws vanuit het Europese Parlement komt: De General Data Protection Regulation (GDPR) is aangenomen. Deze wet beschermt, na een implementatieperiode van twee jaar, vanaf mei 2018 de dataprivacy van alle Europese inwoners. Daarmee vervangt de GDPR een ruim twintig jaar oude wet (GDPR Portal, 2016-a).
Misschien wel de belangrijkste wijziging is dat de nieuwe wet voor alle persoonlijke data van Europeanen geldt, ongeacht de vestigingsplaats van het bedrijf. Beter gezegd, ook bedrijven van buiten de Europese Unie moeten zich aan de wetgeving houden, zodra ze data van Europeanen verzamelen of gebruiken.
In de nieuwe wetgeving zijn een aantal rechten voor ‘data subjects’ (individuele gebruikers) vastgelegd: ten eerste, het recht op een notificatie als een breuk in de beveiliging naar alle waarschijnlijkheid resulteert in een risico voor individuele rechten en vrijheden van gebruikers. Nederland kent dergelijke wetgeving al, dit is geregeld in de Wet Meldplicht Datalekken die in januari 2016 inging (AP, z.d. -a). Ten tweede, het recht om de verzamelde data te ontvangen, gratis en in een leesbaar format. Ten derde, het recht om ‘vergeten te worden’. Hierbij verkrijgt een individu het recht om, naast het inzien van de data, te bepalen dat deze gewist moet worden of dat deze van verder gebruik uitgesloten moet worden. Wat mij betreft is het een geschikte manier om de gelijkheid tussen digitale reuzen als Google en Facebook aan de ene kant en individuele gebruikers aan de andere kant, te bevorderen. Ook is het een eerste stap om het machtsmisbruik van databedrijven aan banden te leggen en dat is hard nodig. Nog geen twee maanden geleden, op 16 mei 2017, publiceerde de Nederlandse privacy-waakhond, de Autoriteit Persoonsgegevens (AP) een rapport over het gebruik van persoonsgegevens door Facebook. De AP concludeert dat Facebook gebruik maakt van “bijzondere gegevens van gevoelige aard”, zoals de seksuele geaardheid, religie-gerelateerd zoekgedrag en gezondheid-gerelateerd zoekgedrag, zonder daarvoor uitdrukkelijke toestemming te vragen. (AP, 2017, p. 163) Ook informeert Facebook de gebruiker onvoldoende over “het doorlopend volgen van een significant percentage van hun surfgedrag en appgebruik buiten de Facebook-dienst, zelfs als ze zijn uitgelogd.” (AP, 2017, p. 156) Het aan banden leggen van de hoeveelheid data die verzameld wordt is goed nieuws in de strijd tegen filterbubbels. Minder data en minder kansen om te personaliseren, al is dat waarschijnlijk slechts een korte-termijneffect. Van grotere impact is dat dit rapport en deze nieuwe wet in mijn ogen beiden een aanleiding zijn om in de toekomst op een andere manier na te denken over de invloed die we databedrijven willen, of dúrven geven.
Om te bepalen in hoeverre deze nieuwe wet in staat is om het effect van ‘Big Data’ op onze samenleving te reduceren, keek ik naar de individuele rechten op informationele privacy die hierop van toepassing zijn. Een veelgebruikte definitie van informationele privacy is die van James H. Moor: “the right to control of access to personal information” (Moor, 1989). Grofweg is deze definitie op te delen in vier elementen: ten eerste richt het zich op de quest naar informatie over iemand. Ten tweede refereert het aan persoonlijke informatie, of dat nou gaat om bijvoorbeeld de identiteit, hobby’s, interesses of gewoonten, of om andere informatie over de gebruiker. Ten derde is er sprake van een zekere vorm van controle over (in dit geval) de data. Kan de gebruiker kiezen welke en hoeveel informatie wordt achterhaald? En als laatste, maar niet als minst belangrijke: het betreft hier een recht. Een recht is wettelijk vastgelegd en dient daarmee gerespecteerd en beschermd te worden (McFarland, z.d.).
Privacy selfmanagement
De General Data Protection Regulation (GDPR) gaat impliciet uit van het model dat Daniel J. Solove ‘privacy selfmanagement’ noemt. (Solove, 2013) Daarbij worden individuen geacht om zelf de afweging te maken tussen de kosten en baten van het delen van persoonlijke data. Er bestaat echter veelvuldige kritiek op dit systeem omdat het te betwijfelen valt in welke mate individuen daartoe in staat zijn. Voor de argumentatie van dit standpunt worden de volgende uitgangspunten gebruikt: 1) het zeer snel veranderende technologische landschap, 2) het feit dat mensen de gebruiksvoorwaarden over het algemeen lezen noch begrijpen, 3) het onvermogen van gebruikers om de impact van het delen van data accuraat in te schatten en 4) het onvermogen om de veelheid aan data te overzien.
1) Een landschap waarin innovatie soms eerder een doel dan een middel is, zo zou het internet vandaag de dag omschreven kunnen worden. De mogelijkheden lijken iedere dag uit te breiden, daarmee ook de effecten op gebruikers. Up-to-date blijven en een constante waarborg van uw persoonlijke privacy is hierin een illusie, als de verantwoordelijkheid bij het individu ligt. Vergelijkend onderzoek bij iedere wijziging moet dan uitwijzen of de gebruiker nog steeds akkoord gaat met de voorwaarden. Wanneer de wijzigingen aangebracht worden en in welke vorm, is vooraf niet bekend. Naar mijn inschatting biedt de GDPR hiervoor nog geen oplossing, omdat een actieve benadering van de gebruiker over specifieke wijzigingen en impact niet expliciet verplicht gesteld wordt.
2) In 2008 kwamen wetenschappers McDonald en Cranor tot de schatting dat het bij benadering 244 uur per jaar zou kosten om alle voorwaarden die we accepteren te lezen (McDonald & Cranor, 2008). Dat zijn ruim 30 achturige werkdagen per jaar. Zo gesteld is het een stuk begrijpelijker dat het grootste gedeelte van de gebruikers op akkoord drukt, zonder gelezen te hebben waarmee ze akkoord gaan. Daarnaast kunnen we stellen dat het volledig lezen van de voorwaarden sterk ontmoedigd wordt. Dit juridisch geformuleerde document, van vaak tientallen pagina’s lang, is nauwelijks begrijpelijk te noemen. Deze ellenlange ‘terms and conditions’, vol onbegrijpelijke en juridische taal, moet verdwijnen, zo concludeerde het EU Parlement. Toestemming voor het verzamelen en gebruiken van data moet duidelijk zijn en het intrekken van toestemming moet gemakkelijker worden. De voorwaarden moeten in beknopte en duidelijke taal worden opgesteld. Belangrijk om hierbij te vermelden is de waarschuwing die professor Media, Culture and Communication and Computer Science aan de Universiteit van New York, Helen Nissenbaum, verwoordde in haar essay ‘A Contextual Approach to Privacy Online’. Ondanks het doel om informatieovervloed te voorkomen leidt het simplificeren van mededelingen ook tot onvoldoende gedetailleerde informatievoorziening, met als gevolg dat mensen onvoldoende in staat zijn geïnformeerde keuzes te maken (Nissenbaum, 2011, p. 59).
Daarnaast blijft het, leesbare teksten of niet, de vraag of de voorwaarden dan wél gelezen worden. In verschillende studies hiernaar, waaronder van de eerdergenoemde Lorrie Cranor waarin creatieve en praktische geboden oplossingen werden, bleek dit onvoldoende te zijn (Yeung, 2016, p.9). Geruststellender is de aanvullende maatregel die in de General Data Protection Regulation beschreven staat onder de noemer ‘Privacy by design’ (GDPR Portal, 2016-a). De Nederlandse Autoriteit Persoonsgegevens zegt hier het volgende over: “Privacy by design houdt in dat u als organisatie al tijdens de ontwikkeling van producten en diensten ten eerste aandacht besteedt aan privacyverhogende maatregelen. (…) Ten tweede houdt u rekening met dataminimalisatie: u verwerkt zo min mogelijk persoonsgegevens, dat wil zeggen alleen de gegevens die noodzakelijk zijn voor het doel van de verwerking” (AP, z.d. -b). Verder schrijft de GDPR een restrictie op de toegang tot persoonlijke data voor.
3) Hoe kwetsbaar bent u precies, als vreemden meekijken met uw datagebruik? Dat is geen eenvoudige vraag om te beantwoorden. Het grootste deel van de mensen is zich wel bewust van bijvoorbeeld de gevoeligheid van bankgegevens, identiteitspapieren of van seksualiteit-gerelateerde gegevens, maar daarbuiten is vaak veel discussie mogelijk.
Veel individuele besluiten komen tot stand op basis van onbewuste, passieve gedachten, in plaats van actieve, bewuste beraadslaging. Dat concludeert de Israëlisch-Amerikaanse psycholoog Daniel Kahneman (2013) in zijn internationale bestseller Thinking, Fast and Slow. Daarnaast blijkt dat het privacy-gerelateerde gedrag van individuen sterk beïnvloed wordt door signalen uit de omgeving (Acquisti, 2015). Hierbij valt bijvoorbeeld te denken aan standaardinstellingen en ontwerpkeuzes die gedrag aanmoedigen of ontmoedigen, zoals lettergrootte en kleurgebruik. Ook gedrag van anderen is van invloed en aangezien discussies over privacy slechts zelden als ‘breekpunten’ bij het gebruik van (sociale) media gezien worden, valt te beargumenteren dat dit geen waakzaamheid bij de gebruikers in de hand werkt. Eerder is het tegenovergestelde het geval. Als laatste dienen we de invloed van verslaving mee te nemen. Social-mediaverslavingen vertonen dezelfde kenmerken als gokverslavingen, waarbij ernstige twijfel ontstaat over de capaciteit van het individu om een verstandige beslissing te nemen. Hij of zij is immers verslaafd (Dow Schull, 2012). Professor Joel E. Cohen van de Rockefeller University in New York City is helder over de langetermijneffecten: “Like so many addictions, our short term cravings are likely to be detrimental to our long term well-being. By allowing ourselves to be surveilled and subtly regulated (…) we may be slowly but surely eroding our capacity for authentic processes of self-creation and development” (Cohen, 2012).
4) We gebruiken veel verschillende diensten. Sommigen maken zelfs gebruik van honderden diensten, met ieder verschillende voorwaarden. De General Data Protection Regulation beperkt het aantal diensten of privacyvoorwaarden niet, maar stelt (zoals bij punt 2 beschreven is) wel dat deze in omvang beperkter en bovendien leesbaarder moeten worden (GDPR Portal, 2016-b). Echter, dan nog steeds komt het maken van een evenwichtige en geïnformeerde beslissing neer op het regelmatig controleren van de gebruiksvoorwaarden van alle diensten die over jouw gebruikersdata beschikken. Zelfs als we het feit dat gebruikers niet altijd weten welke bedrijven over hun gegevens beschikken, buiten beschouwing laten: een onmogelijke opgave.
Bij het reguleren van databedrijven in het algemeen of dataverzameling specifiek, moeten beleidsmakers mijns inziens één basisprincipe scherp voor ogen houden. De gebruikers zijn niet de klanten. Wat ze wel zijn? Dat is tweeledig: 1) Gebruikers zijn, als proefkonijnen of laboratoriumratten in de tredmolen, onderdeel van een sociaal experiment. Of, 2) ze zijn een onderdeel van het product. Het platform (bijvoorbeeld Facebook) is te vergelijken met een fabriek. De gebruiker is een van de grondstoffen. En de bedrijven die de data kopen en er advertenties op baseren, dát zijn de klanten. Als laatste hebben we nog het slachtoffer: onze collectieve portemonnee.
Een verkiezing manipuleren: hoe werkt dat?
Theoretische verhalen over mogelijke beïnvloeding blijven altijd op afstand. Tot ik een artikel van Maurits Martijn (2014), Correspondent Technologie & Surveillance bij De Correspondent, las. Het artikel is drie jaar oud, maar vandaag net zo relevant als toen: ‘Wat heb je tegenwoordig nodig om verkiezingen te manipuleren? Een mediamonopolie? Knokploegen? Omgekochte medewerkers in het stemlokaal? De controle over het Google-algoritme is genoeg’. Martijn wijst op een onderzoek van onderzoekspsycholoog Robert Epstein (2015, American Institute for Behavioral Research and Technology in Vista, California) naar beïnvloeding van verkiezingen in India. ‘Epstein verdeelde zijn proefpersonen (…) over drie verschillende groepen. Iedere proefpersoon kreeg de opdracht te googelen naar de lijsttrekkers van de drie grootste partijen van India’ (Martijn, 2014). De zoekresultaten waren gemanipuleerd. Bij de ene groep stonden de positieve artikelen over een kandidaat bovenaan, bij de andere twee groepen onderaan. Er waren geen berichten weggelaten, dus alleen de rangschikking was afwijkend (Epstein, 2015). De resultaten waren dat ook. Volgens het onderzoek kon op deze wijze het aantal stemmen met 12 procent verhoogd worden. In zijn recentere onderzoek (augustus 2015) was Epstein naar eigen zeggen ‘able to boost the proportion of people who favored any candidate by between 37 and 63 percent after just one search session’ (Epstein, 2015).
Opvallend is dat in mei 2014 de kandidaat die gesteund werd door megaconcern Facebook de verkiezingen won. Eerder dat jaar bezocht Zuckerberg (CEO Facebook Inc.) meermaals Indiase projecten waar Facebook voor internettoegang zorgde. De social media staff van president Modi zei tegen The Guardian dat ‘Facebook was extraordinarily responsive to requests from the campaign, and recalled that Das (top lobbyist van Facebook, red.) “never said ‘no’ to any information the campaign wanted.” Facebook benadrukte dat het bedrijf ‘had never provided special information or extra details to Modi’s campaign’ (Bhatia, 2016). Benadrukt moet worden dat er niet onomstotelijk kan worden vastgesteld dat Facebook een verkiezing naar haar eigen hand gezet heeft.
Het beïnvloeden van stemmen gaat ver, aangezien dergelijke acties het democratische bestel in fundering aantasten. Zélfs als Facebook in haar privacyvoorwaarden de verregaande suggestie van Karen Yeung (2016, p.12), professor bij King’s College London, zou opvolgen: “The content of your newsfeeds is determined by an algorithm that has been constructed in ways intended to encourage you to favour the views of political candidates favoured by Facebook”. Echter, in dit geval kunnen gebruikers, na het lezen van de voorwaarden, zelf de afweging maken om ofwel het account op te zeggen of akkoord te gaan. Dit in plaats van misleid te worden door de beschikbare informatie en vooral het ontbreken van tegenstrijdige informatie. Communicatietechnologie schept in steeds grotere mate ons wereldbeeld, zegt ook Peter-Paul Verbeek van de Universiteit van Twente: “(…) mediating artifacts co-determine how reality can be present for and interpreted by people. Technologies help to shape what counts as ‘real’.” (Verbeek, 2006, p.9)
Ondanks dat het verhogen van transparantie een waardevolle toevoeging kan zijn wil ik benadrukken dat daarmee niet voldaan wordt aan de verantwoordelijkheden die platforms als Facebook en Google hebben. Maar weinig wereldburgers maken géén gebruik van Google en een teruggang in het gebruik, zeker door privacyvoorwaarden, is onwaarschijnlijk. De dienst heeft zichzelf onmisbaar gemaakt. Mede daarom kan in twijfel worden getrokken of het specificeren van de weggelaten informatie voldoende is. Rechtenprofessor Frank Pasquala van University of Maryland (Baltimore, Maryland) sprak zich in 2016 uit over verkiezingsbeïnvloeding door zoekmachines: ‘As a matter of election regulations, I would foresee a future where the Federal Election Commission (onafhankelijk toezichtsorgaan voor verkiezingscampagnes in de VS, red.) was given authority to investigate this issue’ (Schultz, 2016).
Samenvatting
In deze paper heb ik laten zien hoe datahonger en filterbubbels ons dagelijks leven beïnvloeden. Ten eerste toonde ik aan dat personalisatie van informatie resulteert in personalisatie van waarheden. Als een samenleving geen gemeenschappelijke waarheden heeft, is zij per definitie tot op het bot verdeeld. De gepersonaliseerde selectie door databedrijven als Google en Facebook strekt daarmee tot in de haarvaten van de democratie. De meest verontrustende feiten wat betreft zogeheten filterbubbels is dat niet te zien is op basis van welke data er keuzes zijn gemaakt en welke informatie eruit gehaald is. Op deze wijze ontstaan online luchtbellen waarin filters alleen gelijkgestemden laten meepraten, zonder daarbij de gebruiker te consulteren.
Ten tweede wees ik op de manier waarop de databedrijven Google, Facebook en Tinder gegevens van gebruikers verzamelen, ook als deze als intiem of privé beschouwd worden door diezelfde gebruiker. De 57 ‘signalen’ op basis waarvan zoekresultaten gepersonaliseerd worden bij het gebruik van de Google zoekmachine (Pariser, 2011-b, p. 32), wenste het bedrijf niet verder toe te lichten. Hetzelfde geldt voor Facebook News Feed en het algoritme dat Tinder aanstuurt, deze worden beschouwd als ‘bedrijfsgeheimen’. Tot op zekere hoogte zijn de specificaties van deze genoemde ‘signalen’ bekend vanwege uitvoerige analyse door auteurs als Eli Pariser (‘The Filter Bubble’) en Sander Pleij (Vrij Nederland). Genoemde ‘signalen’ voor de Google zoekmachine zijn: de zoekgeschiedenis en welke browser gebruikt wordt, maar ook de fysieke locatie en het tijdstip van de dag (Pariser, 2011-b, p. 32). Dataverzameling van de eerdergenoemde concerns beperkt zich niet het eigen domein, de informatie wordt gecombineerd. Op basis van deze zogenoemde gebruikersprofielen worden data en advertentieruimte per opbod verkocht.
Ten derde besteedde ik aandacht aan de ongekende schaalgrootte waarop de beïnvloeding van gebruikers plaatsvindt. Hiervoor vergeleek ik de populatie van Facebook met het aantal wereldwijde internetgebruikers. Daarbij kunnen we concluderen dat Facebook wereldwijd voor 57 procent van de internetgebruikers bepaalt wat ze zien, wanneer ze het zien en hoe ze het zien, zo lang ze op dat platform actief zijn. In Nederland gebruikt 80 procent van 15- tot 19-jarigen Facebook. WhatsApp (Facebook Inc.) en YouTube (Google Inc.) zijn nog populairder met respectievelijk 96 en 86 procent (Veer, 2017). Illustratief voor het aantal gebruikers van online dating diensten zijn de cijfers van Elyse Romanp (Romano, 2016) over Tinder (40 miljoen gebruikers, 196 landen) en het aantal downloads (Statistica, 2017b; Statistica, 2017c) van een van de online datingapps in 2016 (ongeveer 151 miljoen, Android en iOS).
Ten vierde concludeerde ik dat kritiek op filterbubbels samen te brengen is tot drie hoofdpunten, te noemen:
1) Internetbedrijven gebruiken onze data voor niet-legitieme redenen
2) Zelfs als de redenen legitiem zijn, is het ethisch twijfelachtig om gebruik te maken van de cognitieve zwakten van een gebruiker;
3) Er is een groot gebrek aan transparantie waarbij controle van algoritmen niet mogelijk is.
Ten vijfde legde ik de nieuwe Europese wet (vanaf mei 2018) genaamd General Data Protection Regulation (GDPR) naast de vier uitgangspunten van ‘privacy selfmanagement’. In dit model van Daniel J. Solove (2013) staan centraal: 1) het zeer snel veranderende technologische landschap, 2) het feit dat mensen de gebruiksvoorwaarden over het algemeen lezen noch begrijpen, 3) het onvermogen van gebruikers om de impact van het delen van data accuraat in te schatten en 4) het onvermogen om de veelheid aan data te overzien.
Daarnaast wees ik erop dat bij het reguleren van databedrijven, beleidsmakers mijns inziens moeten onthouden dat de gebruikers niet de klanten zijn. Hierbij maakte ik de vergelijking met respectievelijk een laboratorium en een regulier productieproces: 1) Gebruikers zijn als laboratoriumratten in de tredmolen. Of, 2) gebruikers zijn een onderdeel van het product. Het platform is te vergelijken met een fabriek.
Afsluitend legde ik de potentiële rol van databedrijven bij verkiezingsbeïnvloeding bloot. Zoekmachines als Google en platforms als Facebook bepalen in grote mate het internetgedrag van gebruikers en spelen daarmee een belangrijke rol in de beeldvorming rondom verkiezingskandidaten.
Niels van Velde
Noten
[1] De term werd in 2011 door Eli Pariser geïntroduceerd in zijn boek ‘The Filter Bubble: What the Internet is Hiding from You’. Een verhelderende TedTalk over het onderwerp is te vinden via https://www.ted.com/speakers/eli_pariser.
[2] ‘Which college should I go to?’ Dit betreft een uitspraak van voormalig Google CEO Eric Schmidt (CEO: 2001-2011) tijdens de ‘Google Press Day’ van 2006. Gedocumenteerd door Eli Pariser in ‘The Filter Bubble’ (p. 35)
[3] Tinder is een gratis online dating-app, gericht op gebruiksgemak. Inloggen gebeurt met een Facebook-account en gebruikers swipen vervolgens, per persoon, naar links (‘nope’) of rechts (‘like’).
[4] Naar eigen zeggen is OkCupid ‘de beste internationale gratis datingsite ter wereld’. Inloggen bij OkCupid gebeurt met een Facebook-account of emailadres. Gebruikers krijgen een ‘match’ (klik) en ‘enemy’ (vijand) percentage te zien. Zo toont de site onderscheid tussen singles die wel of niet bij de gebruiker passen. Premium account voordelen zijn betaald.
Literatuur
Acquisti, A., Brandimarte, L., & Lowenstein, G. (2015). Privacy and Human Behavior in the Age of Information. Science, 347, 509-14.
AP (2017) Onderzoek naar het verwerken van persoonsgegevens van betrokkenen in Nederland door het Facebook-concern. Geraadpleegd op 29 mei 2017, van https://autoriteitpersoonsgegevens.nl/sites/default/files/atoms/files/onderzoek_facebook.pdf
AP (z.d. -a) Meldplicht datalekken. Geraadpleegd op 29 mei 2017, van https://autoriteitpersoonsgegevens.nl/nl/onderwerpen/beveiliging/meldplicht-datalekken
AP (z.d. -b) Privacy by design. Geraadpleegd op 29 mei 2017, van https://autoriteitpersoonsgegevens.nl/nl/zelf-doen/privacycheck/privacy-design
Badoo. (2017). Badoo is het grootste sociale ontdekkingsnetwerk ter wereld. Geraadpleegd op 6 juli 2017, van https://team.badoo.com/
Bhatia, R, (2016). The inside story of Facebook’s biggest setback. Geraadpleegd op 20 juni 2017, van https://www.theguardian.com/technology/2016/may/12/facebook-free-basics-india-zuckerberg
Blauw, T. (2014). Google stopt ook met doorzoeken Gmail van bedrijven en overheden. Geraadpleegd op 1 juli 2017, van https://tweakers.net/nieuws/95720/google-stopt-ook-met-doorzoeken-gmail-van-bedrijven-en-overheden.html
Brock, T., & Balloun, J. (1967). Behavioral receptivity to dissonant information. Journal of Personality and Social Psychology, Vol 6(4, Pt.1)
Carr, A. (2016). I Found Out My Secret Internal Tinder Rating And Now I Wish I Hadn’t. Geraadpleegd op 25 mei 2017, van https://www.fastcompany.com/3054871/whats-your-tinder-score-inside-the-apps-internal-ranking-system
Cohen, J. (2012). Configuring the Networked Self. New Haven: Yale University Press.
Dow Schull, N. (2012). Addiction by Design. New Jersey: Princeton University Press.
Edelman (2017). 2017 Edelman Trust Barometer – Global Report. Geraadpleegd op 26 mei 2017, van http://www.edelman.com/global-results/
Epstein, R. (2015). How Google Could Rig the 2016 Election. Geraadpleegd op 20 juni 2017, van http://www.politico.com/magazine/story/2015/08/how-google-could-rig-the-2016-election-121548
GDPR Portal. (2016-a). GDPR Portal: Site Overview. Geraadpleegd op 29 mei 2017, van http://www.eugdpr.org/eugdpr.org.html
GDPR Portal. (2016-b). GDPR Key Changes. Geraadpleegd op 29 mei 2017, van http://www.eugdpr.org/the-regulation.html
Gorris, H. (2016). Het Leek Nieuws, Maar Je Gelooft Nooit Wat Er Toen Gebeurde. Geraadpleegd op 26 juni 2017, van https://www.nrc.nl/nieuws/2016/03/22/arme-gezinnen-lopen-kans-kinderen-kwijt-te-rakenwo-1601095-a524585
Greene, D. (2017). As G Suite gains traction in the enterprise, G Suite’s Gmail and consumer Gmail to more closely align. Geraadpleegd op 1 juli 2017, van https://www.blog.google/products/gmail/g-suite-gains-traction-in-the-enterprise-g-suites-gmail-and-consumer-gmail-to-more-closely-align/
Iyengar, S., & Morin, R (2006). Red Media, Blue Media. Geraadpleegd op 20 juni 2017, van http://www.washingtonpost.com/wp-dyn/content/article/2006/05/03/AR2006050300865.html
Kahneman, D. (2013). Thinking, Fast and Slow. New York: Farrer, Strauss and Giroux.
Lanzing, M. (2016). Privacy is geen luxe, maar noodzaak. Geraadpleegd op 28 juni 2017, van http://www.volkskrant.nl/opinie/privacy-is-geen-luxe-maar-noodzaak~a4379721/
Luckerson, V. (2015). Here’s How Facebook’s News Feed Actually Works. Geraadpleegd op 26 juni 2017, van http://time.com/collection-post/3950525/facebook-news-feed-algorithm/
McFarland, M. (z.d.) What is Privacy? Geraadpleegd op 29 mei 2017, van https://www.scu.edu/ethics/focus-areas/internet-ethics/resources/what-is-privacy/
Moor, J. (1989). How to Invade and Protect Privacy with Computers. The Information Web: Ethical and Social Implications of Computer Networking, Boulder, CO: Westview Press (1989): 57-70.
Nissenbaum, H. (2011). A Contextual Approach to Privacy Online. Daedalus. 140 (4), 32-48.
Pariser, E. (2011-a). Beware online “filter bubbles”. Geraadpleegd op 26 mei 2017, van https://www.ted.com/talks/eli_pariser_beware_online_filter_bubbles
Pariser, E. (2011-b). The Filter Bubble: What the Internet is Hiding from You. London, VK: Penguin.
Pleij, S. (2017). Facebookisme: het nieuwe totalitaire bewind. Geraadpleegd op 17 juni 2017, van https://www.vn.nl/facebookisme/
Romano, E. (2016). The Evolution Of Tinder: How The Swipe Came To Reign Supreme
Tinder. Geraadpleegd op 25 mei 2017, van https://www.datingsitesreviews.com/article.php?story=the-evolution-of-tinder-how-the-swipe-came-to-reign-supreme
Schultz, D. (2016). Could Google influence the presidential election? Geraadpleegd op 29 juni 2017, van http://www.sciencemag.org/news/2016/10/could-google-influence-presidential-election
Solove, D. (2013). Privacy Self Management and the Consent Dilemma. Harvard Law Review 126, 1880-93.
Statista. (2016). Number of internet users worldwide from 2005 to 2016 (in millions). Geraadpleegd op 26 juni 2017, van https://www.statista.com/statistics/273018/number-of-internet-users-worldwide/
Statista. (2017a). Number of monthly active Facebook users worldwide as of 1st quarter 2017 (in millions). Geraadpleegd op 26 juni 2017, van https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/
Statista. (2017b). Most popular Android dating apps worldwide as of July 2016, by downloads (in millions). Geraadpleegd op 25 mei 2017, van https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/
Statista. (2017c). Most popular iOS dating apps worldwide as of July 2016, by downloads (in millions). Geraadpleegd op 25 mei 2017, van https://www.statista.com/statistics/607160/top-ios-dating-apps-worldwide-downloads/
Torbati, Y. (2017). Trump administration approves tougher visa vetting, including social media checks. Geraadpleegd op 20 juni 2017, van http://www.reuters.com/article/us-usa-immigration-visa-idUSKBN18R3F8
Veer, N. van der. (2017). Social media onderzoek 2017. Geraadpleegd op 26 mei 2017, van http://www.newcom.nl/index.php?page=socialmedia2017
Verbeek, P.-P. (2006). Materializing Morality: Design Ethics and Technological Mediation. Science Technology & Human Values, 31, 361.
Wijnberg, R. (2016). Waar is wat klikt. Geraadpleegd op 26 juni 2017, van https://decorrespondent.nl/5951/waar-is-wat-klikt/2207847791402-5166b30f
Yeung, K. (2016). ‘Hypernudge’: Big Data as a Mode of Regulation by Design. Information, Communication & Society. Volume 20, 2017 – Issue 1: The Social Power of Algorithms.
Zuboff, S. (2016). The Secrets of Surveillance Capitalism. Geraadpleegd op 20 juni 2017, van http://www.faz.net/aktuell/feuilleton/debatten/the-digital-debate/shoshana-zuboff-secrets-of-surveillance-capitalism-14103616.html